Common advice when analyzing or improving the structural quality of a system is to aim for a separation of concerns in order to create loosely coupled, highly cohesive code.
In this post we will discuss the first C of structural quality: the separation of concerns. What does it mean, how does it contribute to structural quality and how can we apply it to our code?
Ordering of One’s Thoughts
Edsger Dijkstra is not only one of the founders of the profession we now call software development, but he also coined the term separation of concerns. Citing a letter to one of his professional friends, he writes in his paper On the role of scientific thought (EWD447):
Let me try to explain to you, what to my taste is characteristic for all intelligent thinking. It is, that one is willing to study in depth an aspect of one’s subject matter in isolation for the sake of its own consistency, all the time knowing that one is occupying oneself only with one of the aspects. We know that a program must be correct and we can study it from that viewpoint only; we also know that it should be efficient and we can study its efficiency on another day, so to speak. In another mood we may ask ourselves whether, and if so: why, the program is desirable. But nothing is gained —on the contrary!— by tackling these various aspects simultaneously.
It is what I sometimes have called “the separation of concerns”, which, even if not perfectly possible, is yet the only available technique for effective ordering of one’s thoughts, that I know of. This is what I mean by “focussing one’s attention upon some aspect”: it does not mean ignoring the other aspects, it is just doing justice to the fact that from this aspect’s point of view, the other is irrelevant. It is being one- and multiple-track minded simultaneously.
— Dijkstra, E.W. (1974). On the role of scientific thought (EWD447), p. 0-1.
Dijkstra refers to concerns a program designer should be mindful of, not necessarily the concerns within a program! A designer should focus on one concern at a time, yet be mindful of other important aspects for a successful design.
This view is illustrated in his 1976 book A Discipline of Programming, in which Dijkstra demonstrates mathematical formalism, performance efficiency and structural “beauty” as distinct concerns:
A final remark is not so much concerned with our solution as with our considerations. We have had our mathematical concerns, we have had our engineering concerns, and we have accomplished a certain amount of separation between them, now focussing our attention on this aspect and then on that aspect.
While such a separation of concerns is absolutely essential when dealing with more complicated problems, I must stress that focussing one’s attention on one aspect does not mean completely ignoring the others. In the more mathematical part of the design activity we should not head for a mathematically correct program that is so badly engineered that it is beyond salvation. Similarly, while “trading” we should not introduce errors through sloppiness, we should do it carefully and systematically; also, although the mathematical analysis as such has been completed, we should still understand enough about the problem to judge whether our considered changes are significant improvements.
— Dijkstra, E.W. (1978). A Discipline of Programming, p. 56.
Complex software is like a puzzle, in which each piece has its role to play. The separation of concerns allows for each piece to be carefully considered and addressed, resulting in a successful and satisfying final product. Furthermore, Dijkstra underlines an important implication of the separation of concerns. Being mindful of our application’s concerns in isolation allows us to intentfully trade between them!
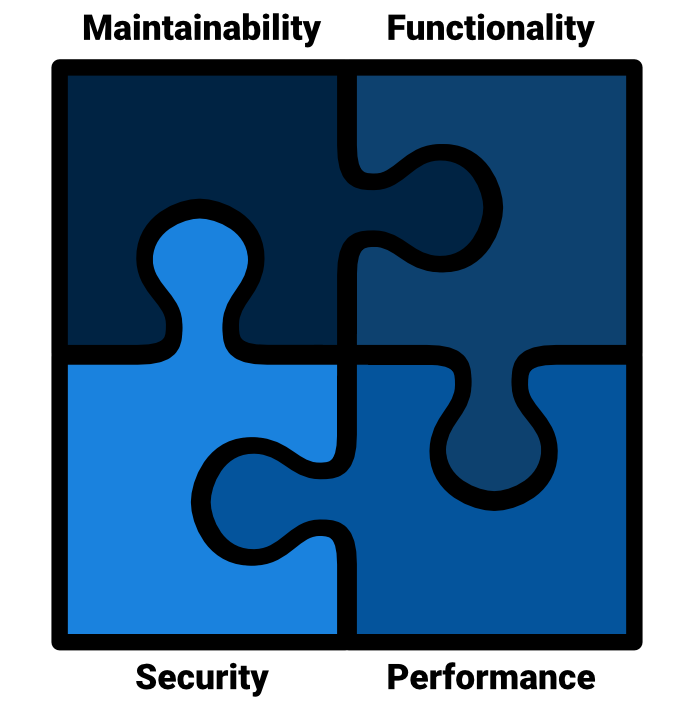
Dijkstra’s separation of concerns means thinking of our quality attributes in isolation, while being mindful of the fact that they’re part of a larger whole.
Through the years, software developers needed to find ways to address all of the concerns their programs required. Arguably, the built-in ability to separate concerns as a program designer was one of the early selling points for the C programming language:
Many studies have shown that most programs spend 50 percent or more of their time in a very small portion (5 percent or so) of their code. This suggests that the 95 percent of the program that is noncritical should be as clear and easy to understand and change as possible. When it comes to the critical 5 percent, C lets the user get very close to the target machine in order to improve efficiency.
(…)
[T]he strategy is definitely: first make it work, then make it right, and, finally, make it fast.
— Johnson & Kernighan (August 1983). “The C Language and Models for Systems Programming” in: Byte Magazine, p. 56
This strategy has since been engrained in the UNIX philosophy and even found its way into the agile community. For instance, the steps involved in modern practices like Test-Driven Development (TDD) as popularized by Kent Beck and others are a form of separation of concerns within the design process:
[Test-Driven-Development] implies an order to the tasks of programming:
- Red – write a little test that doesn’t work, perhaps doesn’t even compile at first
- Green – make the test work quickly, committing whatever sins necessary in the process
- Refactor – eliminate all the duplication created in just getting the test to work
Red/green/refactor. The TDDs mantra.
— Beck, K. (2002). Test-Driven Development: By Example, preface.
We can interpret TDD’s refactor step more broadly as the refinement of other concerns than the functional suitability: e.g. maintainability, performance or usability.
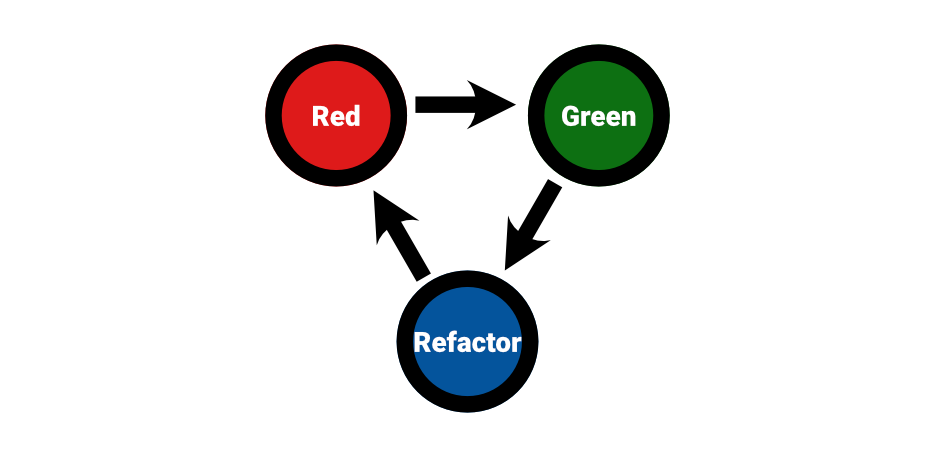
Test-Driven Development aims to deliver working software in small steps while offering us the possibility to focus on one fragment of code and quality attribute at a time.
Separating concerns within the design process allows targeted, incremental cultivation of a system’s quality attributes and prioritization thereof. This process-focused interpretation of separation of concerns is, however, not what people think of when using the term today.
Structured Design
A more common interpretation of the term can be found in the legacy left by the structured design movement, in which Dijkstra’s work played an important role.
One common interpretation of the separation of concerns is to partition the pieces of code that are unrelated and to group those that are. These groupings are not always clear from the start. Often, once a project evolves, we can see the contours of what can be bundled. Core abstractions and system boundaries, for which implementations can vary, are regularly changed independently. Separating along these lines is a good start. As the saying goes: what grows together, goes together.
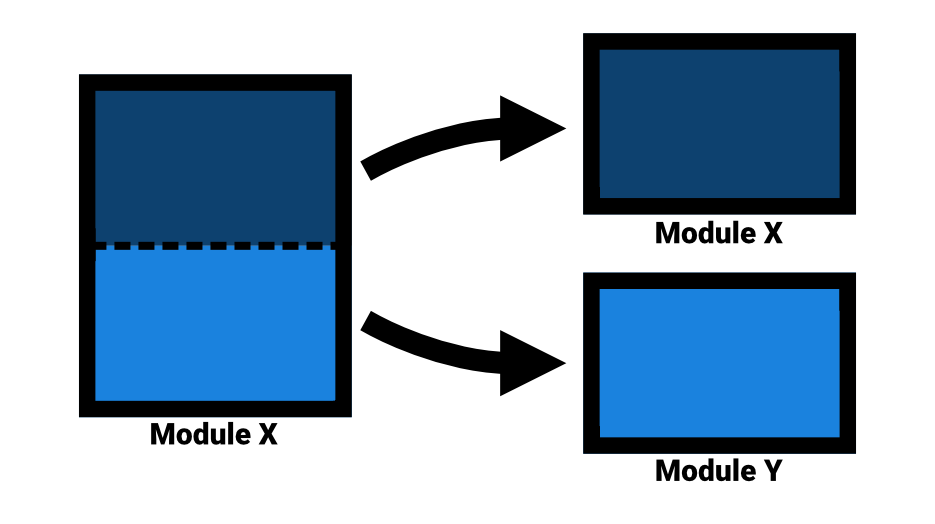
The separation of concerns typically means modularizing our application by separating unrelated modules from each other while grouping those that are related.
Although not referred to as separation of concerns, the idea was central to Yourdon and Constantine’s Structured Design regarding the design of quality software:
[W]e can state the following philosophy: Implementation, maintenance, and modification generally will be minimized when each piece of the system corresponds to exactly one small, well-defined piece of the problem, and each relationship between a system’s pieces corresponds only to a relationship between pieces of the problem.
— Yourdon, E., & Constantine, L. L. (1978). Structured design, p. 18.
Yourdon and Constantine clearly prefer to tackle one small, well-defined piece of the problem at a time , by representing the problem as one small, well-defined piece of the system. Their thoughts on human information processing and program simplicity illustrate why modularization (i.e. the separation of concerns) took such a central role in their book:
We might try taking two separate problems and, instead of writing two programs, create a combined program. Putting two problems together makes them bigger than the two problems taken separately. The primary reason for not combining problems is that, as human beings, we do not deal well with great complexity. As the complexity of a problem increases, we make
disproportionately more mistakes; when problems are combined, we must solve not only each individual problem, but also the interactions between the two (which may involve preventing or avoiding interactions).(…)
It is always easier (and cheaper) to create two small pieces rather than one big piece if the two small pieces do the same job as the single piece.
— Yourdon, E., & Constantine, L. L. (1978). Structured design, p. 62.
Note that when Yourdon and Constantine researched these concepts in the seventies, object-oriented programming was not common ground. Rather, people generally thought about grouping pieces of code in terms of tapes (!), files, procedures and control structures. As part of the structured programming tradition, they looked at ways to combine these in order to design for maintainability and reduce complexity. The tools of the era are illustrated in their definition of a module: “a contiguous sequence of program statements, bounded by boundary elements, having an aggregate identifier”. These ideas are still useful when applied to modern software practice — arguably even more so since we have more design tools at our disposal for grouping and organizing concepts.
Parnas, however, made an important contribution to the concept of modules six years earlier:
We propose (…) that one begins with a list of difficult design decisions or design decisions which are likely to change. Each module is then designed to hide such a decision from the others. Since, in most cases, design decisions transcend time of execution, modules will not correspond to steps in the processing. To achieve an efficient implementation we must abandon the assumption that a module is one or more subroutines, and instead allow subroutines and programs to be assembled collections of code from various modules.
— D.L. Parnas (December, 1972). On the Criteria To Be Used in Decomposing Systems into Modules, Communications of the ACM, p. 1058
This is in principle still how developers tend to see the separation of concerns, although our modularization toolbox has become a bit bigger.
In object-orientation, this separation of concerns is primarily achieved by designing classes and objects and encapsulating state and behaviors inside them. In most languages we can use packages, namespaces and modules as another means of separating concerns. One could argue that independently deployable (micro)services are another level of modularization albeit in a distributed fashion.
The separation of concerns allows us to see the forest for the trees by splitting up general modules into more specific ones.
Managing Complexity = Managing Cognitive Load
Dijkstra’s preference for separate modes of designing and being able to trade off concerns and Yourdon’s and Constantine’s remarks favoring dedicated small pieces over one large piece can be supported by research and theories about human memory, cognition and learning.
One such theoretical model can be found in Atkinson and Shiffrin’s 1968 work Human Memory: A Proposed System and its Control Processes. Their multi-store model of memory, on which lots of research on memory and learning is based, proposes that information flows through a series of stages as it is processed and stored in the brain, and that different types of memory serve different functions in this process. It describes three separate stores of memory in the brain:
-
Sensory registries: temporary storage systems for sensory information, such as sight and sound.
-
Short-term memory (or: working memory): information from the sensory registers is passed on to the short-term memory, which has a limited capacity and duration. This is where reasoning about a problem at hand takes place.
-
Long-term memory: a more permanent store of information that can hold an almost unlimited amount of information. It can be retrieved and used for a variety of purposes, such as problem-solving and decision-making.
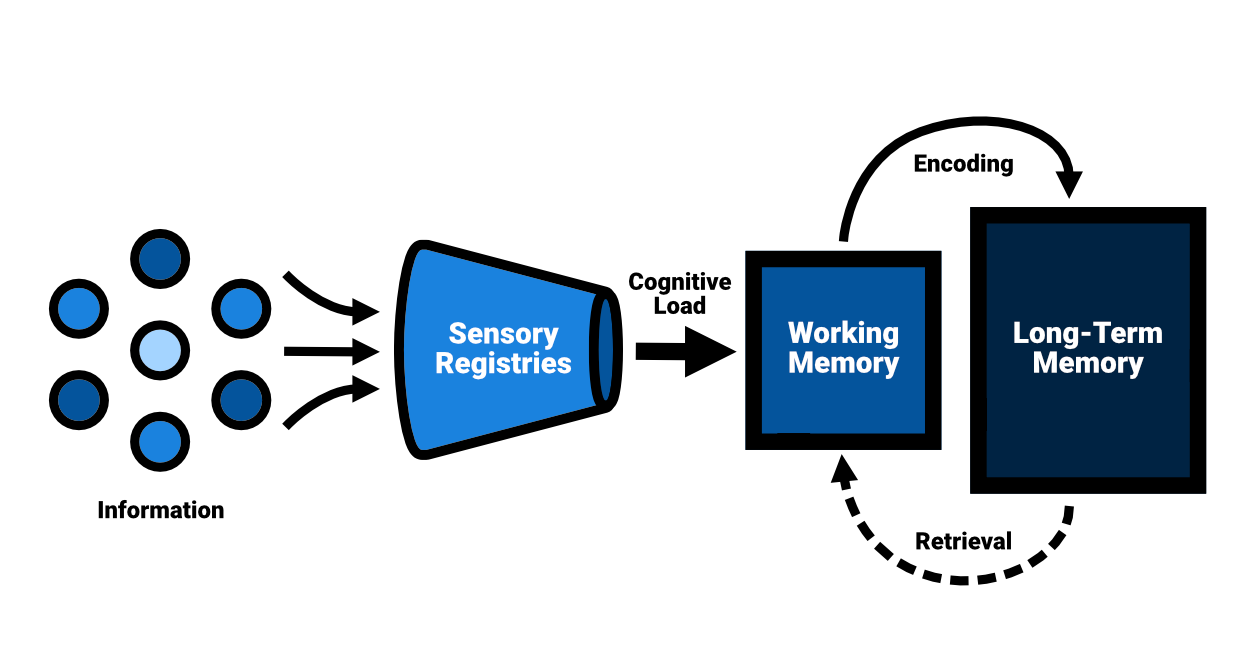
An overview of cognitive architecture, loosely based on Atkinson, R.C. and Shiffrin, R.M. (1968). ‘Human memory: A Proposed System and its Control Processes’.
Applied to the theory of learning, Sweller, Van Merriënboer and Paas summarize this architecture as follows:
(…) We have a limited working memory that deals with all conscious activities and an effectively unlimited long-term memory that can be used to store schemas of varying degrees of automaticity. Intellectual skill comes from the construction of large numbers of increasingly sophisticated schemas with high degrees of automaticity. Schemas both bring together multiple elements that can be treated as a single element and allow us to ignore myriads of irrelevant elements. Working memory capacity is freed, allowing processes to occur that otherwise would overburden working memory.
— Sweller, Van Merriënboer, Paas (1998). Cognitive Architecture and Instructional Design, p. 258.
The knowledge and skills about how to program are embedded into our long-term memory in the form of schemas which group related facts and elements. These include syntax, datastructures and algorithms in general and specific facts about a certain project.
Reading, understanding and improving parts of software project, however, makes use of our working memory. This is where we temporarily store and work on the elements of an issue at hand. These activities cause a load on our working memory: cognitive load. Having to deal with a large amount of elements at once can overload our working memory. This can also happen if we need to work on elements that are too complicated to be understood quickly. An overloaded working memory not only slows us down, it makes us prone to error.
As we work longer with a certain system and get familiar with its core concepts and architecture, we might experience less cognitive load. We have then learned the system. We have committed the knowledge and experience about the system into our long-term memory. This, however, takes time.
A Common Solution
Can we make our systems easier to understand and decrease cognitive load from the other end, while simultaneously making it easier to learn how to work with the system? Instead of dealing with a complex whole, breaking things up can help manage the intrinsic cognitive load of understanding, working with and remembering something. A common strategy to make the intrinsic cognitive load more manageable is is called chunking. (see: Miller (1955), The Magical Number Seven, Plus or Minus Two. Some Limits on Our Capacity for Processing Information). Chunking means compartmentalizing content into smaller but meaningful units, without ignoring the relationship between these units.
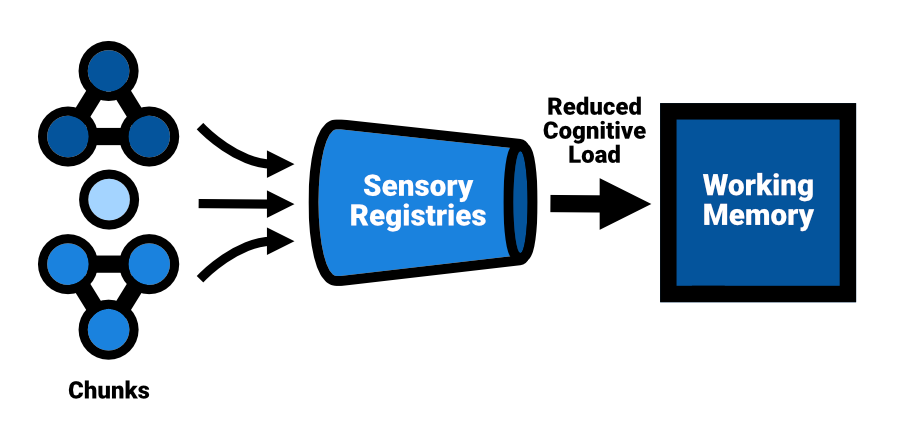
Offering information in related chunks, rather than unorganized data can lead to reduced cognitive load.
Strategies like chunking help establish a stable foundation on which new knowledge and skills can be built. This is what the separation of concerns is all about! We do not want to be concerned with “all details, all at once”. Rather, we want to operate solely on the essence of what is relevant for the task at hand. We want to separate unrelated structures and processes from eachother and only group those which are related. To manage this kind of complexity, we introduce abstractions — not only in software, but in life.
We can find domain-specific abstractions in our code-base (objects, functions, variables), define our system’s boundaries using protocols or make use of a plethora of abstractions, shared by our industry such as design patterns and common architectural styles. These should make it easier not only to understand and work with a system, but also to learn and remember key facts about it.
The Role of Documentation and Tests
A supplemental approach is by explaining the system through worked examples, for instance by offering documentation and tests. Like building furniture with an instruction manual this can make a project easier to understand and learn for newcomers and seasoned developers alike.
Software documentation can help to reduce cognitive load in software systems by providing clear and concise information about the system’s design, functionality, and usage. This information can be presented in various forms, such as code comments, diagrams, and user manuals.
Code comments, for example, provide explanations of the logic and functionality of individual code modules. This can help developers to quickly understand the purpose and usage of a particular module, reducing the cognitive load required to read and understand the code.
Diagrams, such as class diagrams, component diagrams sequence diagrams, can also help to reduce cognitive load by providing a visual representation of the system’s components, their relationships and how they communicate. Like a map in unfamiliar territory, diagrams can help us when were stuck. They can make the system more convenient to navigate and a system’s structure and functionality easier to understand, especially for developers who are new to the project. An approach like Simon Brown’s C4-model could reduce cognitive load even further.
Besides guarding against regressions, (unit) tests can augment documentation by providing concrete examples and proof of the system’s functionality, behavior or properties. Tests provide detailed scenarios in which the system is expected to behave in a certain way. This can serve as a valuable supplement to the high-level descriptions and explanations provided in documentation.
Keep in mind that the separation of concerns also applies to documentation and diagrams. The best documentation is easily searchable and logically divided into chapters, sections and paragraphs. A good diagram does not model too many aspects at once: as an abstract depiction of our problem or solution space, it should omit every detail that does not contribute to its purpose.
Axes of Separation
Projects can be separated around different axes (plural of axis, not tools to cut down trees). In traditional development we often see a separation by technology. This axis is often used in classical front-ends: our presentation (HTML), styling (CSS) and interactivity (JS) are all separated into different files. On the back-end, we see the same in traditional MVC-style monoliths, in which every folder has a technical meaning which is further divided per aspect of functionality rather than the other way around.
A modern approach is based on separation by responsibility. In this approach we pay attention to the role a module plays within a system and group the technologies that fulfill that role. This approach is followed by component-based front-ends: React, Angular, Vue, Svelte, Solid or native Web Components. We also see this role-based approach in component or (micro)service back-ends. A single service or component encapsulates implementation details that, when combined, provide a function within the whole system.
Ideally, these components or services are divided further into responsibility-specific, semantically relevant modules like layers or subsystems. Often, this is represented in code through modules, packages and namespaces. This can make a code-base easier to navigate, and architectures less prone to erode, thus reducing cognitive load.
In Conclusion
The first C of structural quality is the separation of concerns. The term was originally coined to compartmentalize the desired aspects of a piece of code, so one could work on one aspect at a time and trade-off between them.
Nowadays it’s mostly a principle for organizing a program’s structure into meaningful chunks, so that developers don’t have to be mindful of all the complexity of a system, all at once.
Both interpretations aim to reduce the cognitive load on the working memory of the developer, making it easier to understand such a system and work on it. On top of that, it can make it easier to learn and memorize facts about a system to further decrease the cognitive load on the developer’s working memory.
We can achieve this by introducing meaningful abstractions or using common, existing ones. Additionally, documentation like comments, diagrams and manuals can come in handy reducing the cognitive load when understanding and working on a system. Tests can also help grok a system as they are often useful examples of how a piece of code is supposed to operate.
The separation of concerns is a common first step in managing software complexity. We reduce the cognitive load on the developer through a meaningful hierarchy of abstractions, with encapsulated states and behaviors. But how do we organize these abstractions in a way that leads to chunks that are not only understandable but also maintainable? This is where high cohesion and loose coupling come in. The second and third C of our 3Cs of structural quality.
Thoughts?
Leave a comment below!