In a previous post, we have seen messaging primitives: events, commands and queries. In this post, we will take an extensive look at publish-subscribe: a common messaging pattern for decoupled and (near-)realtime communication.
What is publish-subscribe?
In Just Enough Software Architecture (2010), George Fairbanks describes publish-subscribe as an event-based architectural style wherein independent components publish events and other (or the same) components subscribe to them. Fairbanks distinguishes two ports: one for publishing and one for subscribing. A connector (or: event bus or message broker) is also part of the pattern: an intermediary to which many publishing and subscribing components can attach.
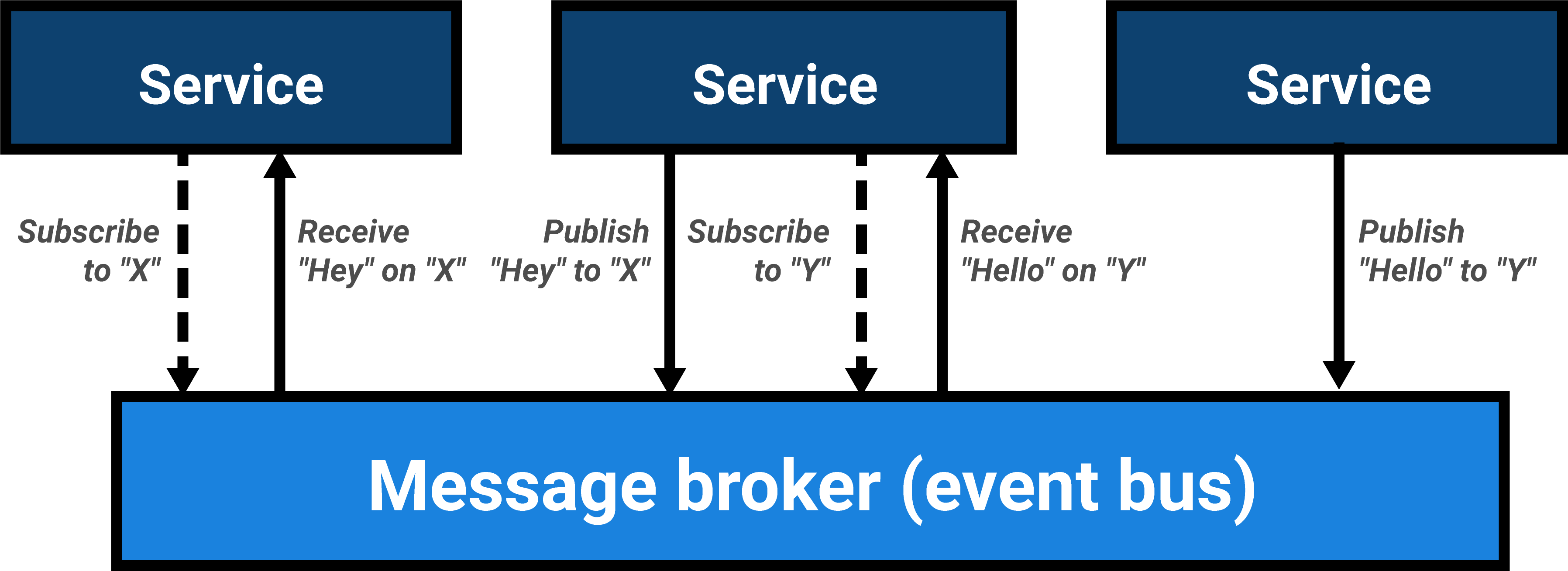
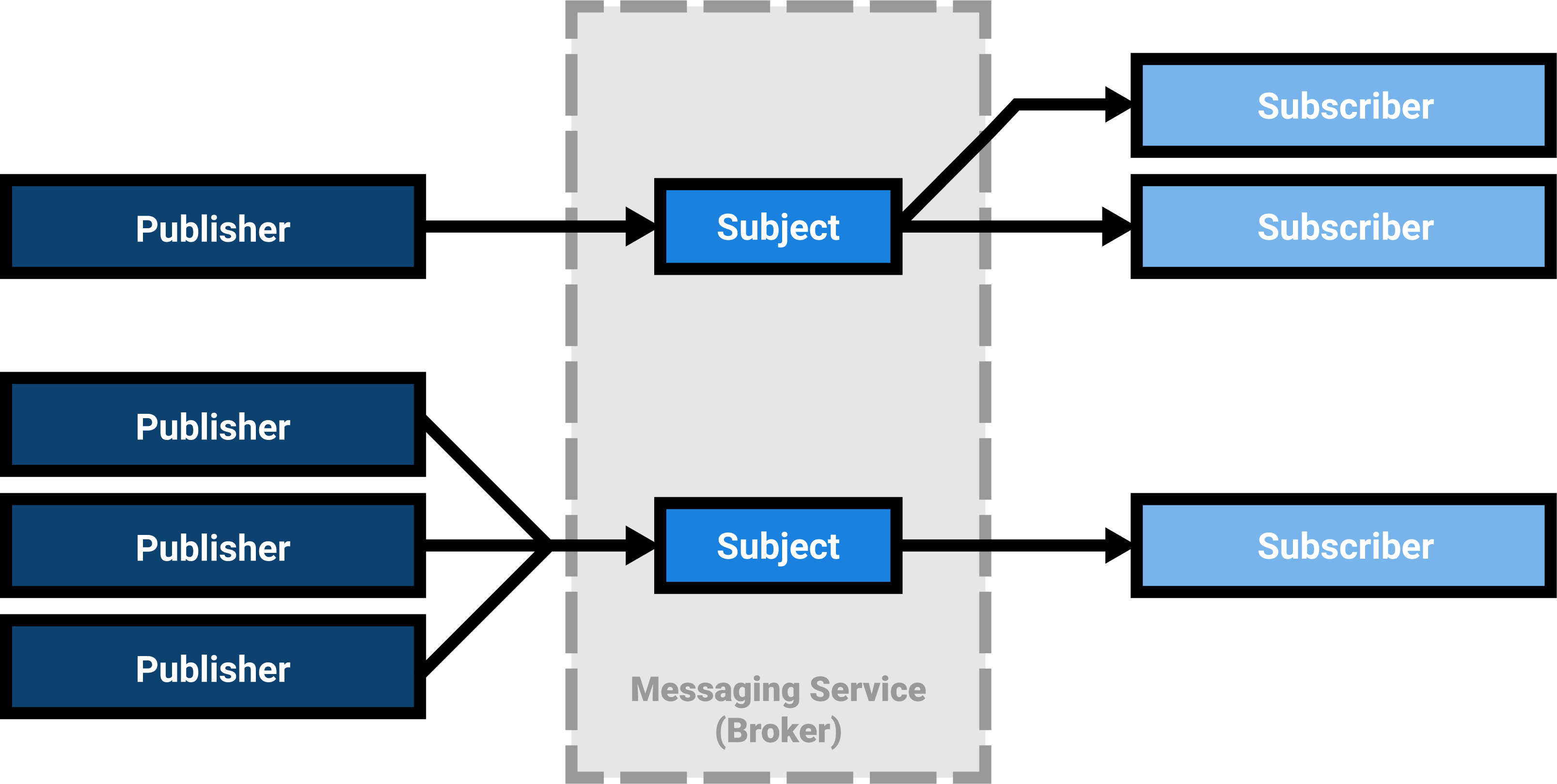
Messages are sent to a channel by a publisher, while subscribers receive messages from the channel of interest. This channel is often called the subject or the topic. Alternatively, in a content-based approach, sending to or receiving from a channel can occur based on the message’s contents.
Reekie and McAdam refer to publish-subscribe as a notification architecture in their book A Software Architecture Primer (2006), p. 116: “components that are interested in events of interest inform a known registration point of their interest; at a later time, when the event occurs, the interested components are notified of the event.”
Fairbanks emphasizes the decoupling of producers and consumers as the biggest benefit of publish-subscribe, resulting in a system that is “more maintainable and evolvable”:
Consider the situation when a new component needs to do work based on an event. It can simply subscribe to that event and the system is otherwise unchanged. Specifically, the event publisher is unchanged. Similarly, a new event publisher can be added without affecting the system, and later a component (new or existing) can begin subscribing to those events.
– Fairbanks, G. (2010). Just Enough Software Architecture, p. 287.
In publish-subscribe, messages are not directed towards individual services, but towards generalized subjects. In other words: publishing components or services can evolve separately from their subscribing counterparts and both are only coupled to the event bus responsible for delivering published event to interested subscribers. Publish-subscribe could be the first step of a decoupled, message-driven architecture and could aid in increasing (micro)service autonomy.
It is good to note that there can be zero to multiple publishers and zero to multiple subscribers for a single topic, so both fan-in (multiple publishers to a subject) and fan-out (multiple subscribers to a subject) are baked into the pattern.
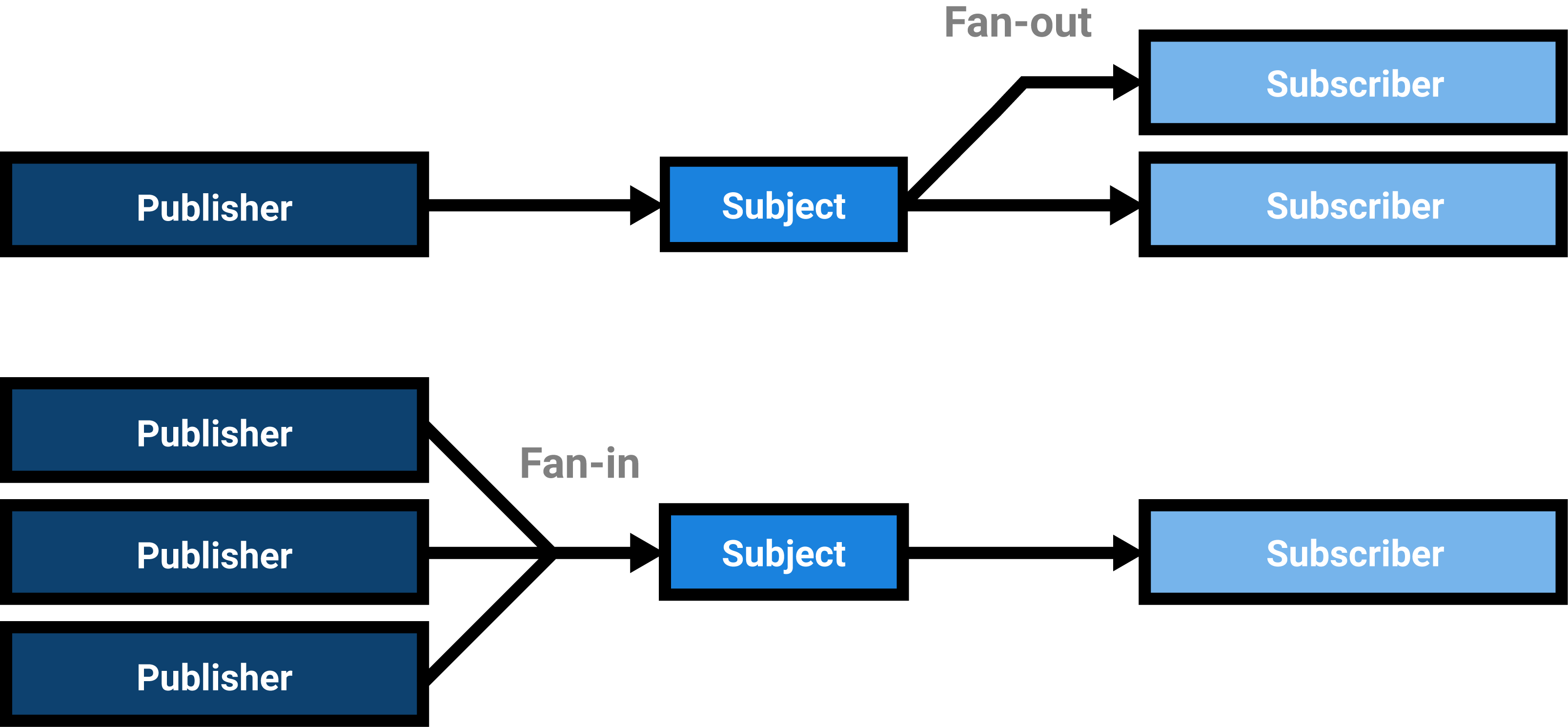
Another interesting aspect of this approach is that it forms a unidirectional dataflow. Data always flows from a single publisher to one or many subscribers, although a component or service can function as a both a publisher or a subscriber for many subjects and a single subject can have multiple publishers. In general, a unidirectional dataflow is easier to reason about because changes will only happen down-stream in reaction to events up-stream. Therefore, for a single interaction, the publisher can be seen as an authorative source to which the subscriber reacts. This allows subscribers to be implemented in a functional and/or reactive manner.
Because of the indirection between publisher and subscriber, the pattern is more often useful for synchronization through event notification than for acting on commands. After all, events are statements of fact, while commands are imperative requests for action. Publish-subscribe is unsuited for responding to queries, because of queries' bidirectional nature.
In contrast to a message queue, messages are typically not batched, nor are they stored: they are pushed to interested subscribers as they are delivered in a fire-and-forget fashion. This is why publish-subscribe implementations commonly offer at-most-once delivery guarantees. A lossy messaging system without additional guarantees could offer great performance and suffices for applications that are not interested in every single message.
If you cannot spare to lose messages, it is possible to increase reliability by adding queues or queue-like durability. Systems that persist messages in order to ensure delivery operate according to at-least-once semantics: mechanisms have been put in place to even deliver the message in the event of network or client failures, although possibly multiple times. This can be achieved, for instance, by resending messages that have not been acknowledged. Although good for reliability, these kinds of mechanisms can reduce performance and increase complexity.
Example brokers
There are a lot of services that function as message brokers. I will shortly touch on three of my favorites: Redis, RabbitMQ and NATS.
Redis, an in-memory key-value datastore, also has support for publish-subscribe messaging when using its pub/sub protocols. For more guarantees, Redis streams can be used.
If you need a tunable and highly configurable message broker, RabbitMQ can be considered. RabbitMQ combines the concepts of a message queues, exchanges and publish-subscribe and adds extra features for added guarantees, such as durability and the handling of undelivered messages.
NATS is a broker supporting high-volume, high-throughput messaging. Although other patterns are supported, NATS' focus lies on publish-subscribe. NATS Streaming is based on NATS and offers more guarantees like persistence and replays.
Characteristics of publish/subscribe architectures
In The Many Faces of Publish/Subscribe by Eugster et al. (2003) three distinctive characteristics of any publish-subscribe mechanism are described: space decoupling, time decoupling and synchronization decoupling.
Space decoupling
This is also known as spatial decoupling or referential decoupling and refers to the fact that the publishers and subscribers do not need to know about one another. There is an intermediary service that orchestrates between them.
Time decoupling
“[Publishers and subscribers] do not need to be actively participating in the interaction at the same time,” Eugster et al. (2003) note. This is also known as temporal decoupling: a subscriber and publisher do not need to be active at the same time. For instance, a publisher can stop running after publishing and the subscriber will still get the message – as long as the message was received (and forwarded) by the intermediary.
In their book Distributed Systems (2017), Tanenbaum and Van Steen note that decoupling in time and space can be achieved by forming a shared data space: the result of combining an event-based architecture with a data-centered architecture. In other words, the amount of temporal decoupling depends on the (durability) guarantees offered by the intermediary message broker.
Synchronization decoupling
Lastly, Eugster et. al (2003) recognize that, in publish-subscribe systems, “publishers are not blocked while producing events, and subscribers can get asynchronously notified (…) of the occurence of an event while performing some concurrent activity.”
Eventual consistency
Keep in mind that, because of the decoupled nature of publisher and subscribe, one treads in the realm of eventual consistency rather than immediate or strong consistency: one cannot assume the subscriber’s state to be in-sync with publisher’s – it will synchronize eventually, after an undefined amount of time.
Interestingly, this can also apply to the act of subscribing: as a subscriber will need to subscribe prior to receiving messages of its interest, it can take a random amount of time before the subscription is received and handled. Depending on the guarantees offered by the intermediary, this means publications done before subscription are not delivered.
Relation to the observer pattern
Publish-subscribe is nowadays often used to describe an architectural pattern at the level of platform architecture, for example as an integration pattern between the services in a service based architecture.
The observer pattern is a similar pattern, although more often used within the context of application architecture for subject-to-observer notification between objects. In their famous design pattern book, the Gang of Four, Gamma et al. (1995), describe the observer pattern’s intent as follows:
Define a one-to-many dependency between objects, so that when one object changes state, all its dependents are notified and updated automatically.
Gamma, E., Helm, R., Johnson, R., Vlissides, J. (1995). Design Patterns, p. 293
In the observer pattern, a subject tracks the state changes of a certain object and notifies observers that are registered to that subject of any state changes that occur.
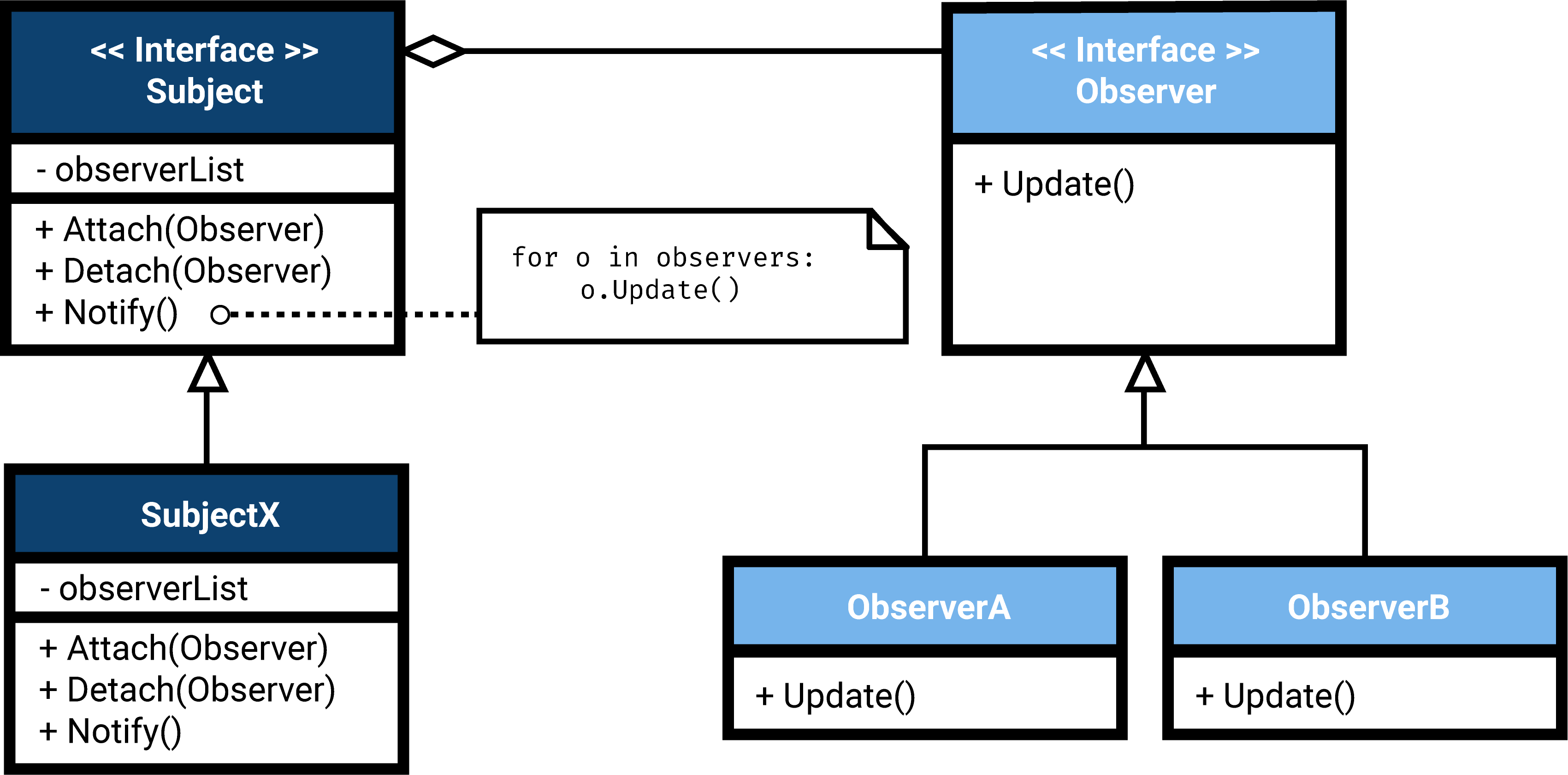
Observers can subscribe to a subject by attaching themselves to it: a subject typically keeps a list of the observers that are subscribed to it. Whenever a subject changes, the known observers are notified of these changes. According to the Gang of Four (Gamma et al., 1995, p. 294), “[t]his kind of interaction is also known as publish-subscribe.” It can therefore be argued that the term publish-subscribe can be used not only for the architectural pattern, but for the broader principle that underpins both observer pattern and the aforementioned publish-subscribe integration pattern: the one-to-many unidirectional notification behavior between publisher and subscriber.
In common implementations of the observer pattern, there is a coupling between observer and subject. If the subject is implemented to be part of the object being observed, a tighter coupling is created as observer and observant need to know about one another. However, in order to have the benefits of publish-subscribe, one should strive to decouple the observer and the observed as much as possible. At an object level, this means separating the subject and observer from the object being observed. The subject then functions as an intermediary to the object being observed (the publisher) and the observer (the subscriber).
Push versus pull
Generally speaking, there are two flavors of publish-subscribe (or the observer pattern): the push model and the pull model.
In the push model, the publisher (subject) sends all the information to subscribers (observers) at once, even if these are not necessarily interested in all the information.
Pulling the details in is at the heart of the pull model. The publisher (subject) publishes a general notification and interested subscribers (observers) can query for more information if need be.
The Gang of Four describe the differences between these models:
The pull model emphasizes the subject’s ignorance of its observers, whereas the push model assumes the subjects know something about their observers' needs. The push model might make observers less reusable, because Subject classes make assumptions about Observer classes that might not always be true.
Gamma, E., Helm, R., Johnson, R., Vlissides, J. (1995). Design Patterns, p. 298
I am not convinced this is broadly applicable to publish-subscribe, especially within the context of a service-based architecture with an intermediary message broker. If the publisher submits some message in a push fashion to a certain subject, subscribers (if any) receive a detailed message but can decide at that moment which contents of the message are of interest to them. The publisher therefore does not assume anything about the existence of subscribers to the subject published to – let alone their specific needs and implementation details.
In the pull-based approach, a one-way notification is followed up by a query in the opposite direction. Of course, one could use another communication pattern for that, such as [request-reply][request-reply], which can either be addressed directly, because of a reference known to the requester or present in the message, or through some broker. However, this requires either a direct coupling between publisher and subscriber or some (reversed) discovery mechanism through the intermediary messaging service, impairing the simplicity and other merits of unidirectional data flow. In that case, it begs the question whether the pull model is actually more reusable than the push model or if it is the other way around.
Risks
Although decoupling in time, space and synchronization sounds great, there are some risks that need attention when basing your architecture around publish-subscribe.
In publish-subscribe, services depend on a single logical messaging service instead of having cross-dependent services. This could introduce a single point of failure in the system, making it fragile from a security and infrastructure standpoint. One way to mitigate this, is to leverage a messaging system that offers availability and fault-tolerance. Keep in mind that this only solves the problem on an infrastructural level.
Although service autonomy is easier to achieve within an eventually consistent system, this also implies services can lag behind due to network issues. In the same vain, some message brokers can have trouble dealing with high load. Messages can be dropped, unless a broker offering delivery and durability guarantees is used. However, such a system can have its own effect on performance and operationality. These issues can cause services to run out-of-sync and messages to not necessarily come in time or in the expected order. Combining publish-subscribe with distribution and message-queues will help alleviate these risks, but it is a good strategy to design services around the principle of autonomy and to embrace asynchronicity and isolation: scale the services that need to scale and protect against services dragging eachother down in the event of a failure.
Lastly, due to its decoupled, message-driven nature, publish-subscribe systems information flow can be difficult to discover or follow. It is advisable to employ tools that subscribe to subjects for instrumentation and monitoring purposes in order to increase observability.
In conclusion
In this post, we have looked at the publish-subscribe pattern from different angles. We have seen that it is a pattern with many faces, but commonly refers to a mechanism which decouples the sender and the receiver of a message through an intermediary. At an object level, publish-subscribe overlaps with the Observer pattern. As an architectural pattern it can be decoupled in time, space and synchronization depending on the guarantees provided by the intermediary message broker.
In a subsequent post, we will use use NATS and Node.js to build a simple functional service-based architecture leveraging the publish-subscribe pattern.
Thoughts?
Leave a comment below!