Some say object orientation is a thing of the past; too ceremonious and unpractical for real use. Although I recognize that some dogmatic approaches have muddied the waters, I think object orientation remains a useful way of thinking about and designing software, also when supplemented with other paradigms.
In this post, we will dive into the building blocks of object orientation to better understand what it is, the instruments it offers and how we can use these instruments to design maintainable software.
The Need for a Model
People create software to solve a problem in an automated fashion. In order to do this, they need to sufficiently understand the problem domain in all its nuances, discern the relevant from the irrelevant details and come up with a solution that not only meets expectations with regards to its functionality, but also suits current and future environments in which it is to be used.
The resulting software needs to deal with complexity yet be easy to understand, maintain and extend by its creator, their team and their successors. This requires people to work together, discuss opportunities and risks and share their understanding of the system-as-is and system-to-be. These are the things that make software engineering difficult and worthy of its own profession.
It is worthwile to take some time at the start of each project, system, component and feature to explore the use cases of the desired outcome, the terms and concepts that live in the domain and the algorithms that best fits the requirements within a structure that remains maintainable.
We sketch a model of the (real-world) problem and possible solutions to understand, communicate and manage complexity — not only in the form of documents and diagrams, but more importantly in our minds and our code. We need a way to reason and talk about all this complexity. As Grady Booch and others note in Object Oriented Analysis & Design with Applications (OOAD):
The task of the software development team is to engineer the illusion of simplicity.
— Booch, G., e.a. (2007). Object Oriented Analysis & Design with Applications, p. 9.
Object Orientation
One way of managing complexity is through object orientation (OO). In this approach, we look at the problem and potential solutions to discover and describe concepts, rather than starting out with infrastructure, algorithms, data structures and data flow. Each concept gets its own structural representation in our code, grouping related behaviors, and facilitating and limiting the interactions between them.
Booch, e.a. describe different activities when working in an object oriented manner:
- object-oriented analysis
- object-oriented design
- object-oriented programming
I don’t think these are to be interpreted as three strictly separated activities, but they represent the general tasks involved when modelling the problem and the solution, whether it is in documents, our minds or our code. They’re not some steps in a formal development lifecycle, but activities we do all the time. And sometimes we do them all at the same time!
Object-Oriented Analysis
At any moment when creating software we can analyse the problem, its proposed or executed solution and possible alternatives. We can do that in an object-oriented manner.
Object-oriented analysis is a method of analysis that examines requirements from the perspective of the classes and objects found in the vocabulary of the problem domain.
— Booch, G., e.a. (2007). Object Oriented Analysis & Design with Applications, p. 42.
I disagree with the notion that we should be thinking of implementation details such as classes and objects when we are examining requirements. Rather, we should think in general responsibilities and break these up in components of related use.
Object-Oriented Design
We can of course use “real-life” objects as a reference or metaphor for thought to achieve an understandable software design.
Object-oriented design is a method of design encompassing the process of object oriented decomposition and a notation for depicting both logical and physical as well as static and dynamic models of the system under design.
— Booch, G., e.a. (2007). Object Oriented Analysis & Design with Applications, p. 42.
In my opinion, notation is not necessarily part of the design itself. It is an expression thereof. That’s why I think the most relevant part of this definition is the fact that the design effort focuses on object oriented decomposition rather than structured design. This means design is done by breaking up a problem in terms of objects rather than by their algorithmic inner workings. A sketch of a system architecture emerges when we group these objects by responsibility and level of abstraction in packages, namespaces or other forms of modular grouping.
Object-Oriented Programming
Because of the variety of programming languages and philosophies, it is difficult to extensively define object-oriented programming.
In the OOAD book it is defined as follows:
Object-oriented programming is a method of implementation in which programs are organized as cooperative collections of objects, each of which represents an instance of some class, and whose classes are all members of a hierarchy of classes united via inheritance relationships.
— Booch, G., e.a. (2007). Object Oriented Analysis & Design with Applications, p. 41.
This description leaves out languages that do not use classes but do have object-oriented capabilities. Examples include JavaScript (in which everything is an object but is primarily prototype-based; although classes have been added later on) and Go and Rust (which center around collections of structs but lack implementation inheritance).
As languages grow into multi-paradigm languages, I think it is valuable to not think of languages as object-oriented but whether a language allows you to reason in terms of real-life objects and organize your code base around that. This might even open up functional programming languages to object-oriented analysis and design. In statically typed functional languages, you can find this kind of object thinking when modelling with functions, abstract data types and the type system. An object can then be thought of as a composition of more fundamental types, data structures and behaviors, all represented in code as separate, standalone concepts.
The Pillars of OO
Although I cannot find the original source, a popular way of explaining object orientation found in tutorials and introductory courses, is through the “Pillars of Object Oriented Programming”. These pillars stand for 3 or 4 properties one can use when designing object-oriented software:
- Abstraction
- Encapsulation
- Inheritance
- Polymorphism
The Pillars are sometimes also used to defined whether a certain language is object-oriented. There are, however, modern languages that are considered object-oriented that do not conform to typical interpretations of these Pillars and one can program using an object-oriented mindset without explicit object-oriented capabilities in the used programming language. I don’t like these pillars because inheritance and polymorphism are not essential to object oriented thinking!
The Object Model
Similar to the Pillars of OO is Booch' Object Model found in the OOAD book, which also describes elements that can be used together to produce an object-oriented model. Booch, e.a. describe four major elements that are essential for a model to be called object-oriented and three minor elements (types, concurrency and persistence) that are useful but not essential.
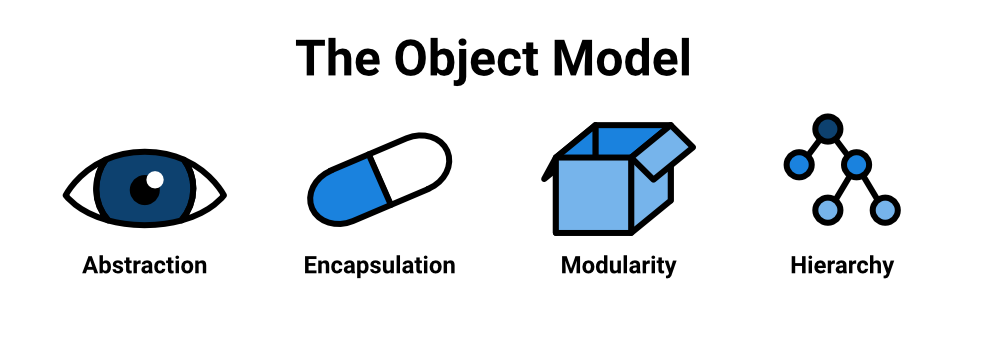
The major elements of the object model are:
- Abstraction
- Encapsulation
- Modularity
- Hierarchy
Let’s see what they are and how they are useful tools for thinking about and designing software.
1. Abstraction
Programming languages are abstractions over the hardware (and the software) they run on. The more high level a language is, the less a programmer needs to be concerned with the inner workings of the machine. They primarily need to pay attention to the essentials of the problem and solution domains and do not have to pay as much attention to whatever happens behind the scenes. They can focus on the what instead of the how. Atleast, that is the promise.
In object-orientation, objects are our principal methods of thought, our primary abstractions. In class-based languages such as C++, C# and Java, objects are instantiations of classes, which carry a type. Objects, classes and types are then the primary mechanisms the developer can use to focus on what matters. These can of course be supplemented by others, such as interfaces, enumerations and functions.
Booch, e.a. describe abstraction as follows:
An abstraction denotes the essential characteristics of an object that distinguish it from all other kinds of objects and thus provide crisply defined conceptual boundaries, relative to the perspective of the viewer.
— Booch, G., e.a. (2007). Object Oriented Analysis & Design with Applications, p. 44.
An abstraction conveys meaning. We use abstractions every day to prevent drowning in details. When someone asks us what we are having for dinner, we usually do not describe it on a molecular level. Often we refer to the name of a dish or, if the listener is unfamiliar with the dish, we describe its ingredients in general terms. If the reason of our conversation, however, is to learn how to prepare the dish, the context of our conversation shifts towards what is inside the dish and how to prepare it. We then discuss the meal’s essentials. These are the details, such as the ingredients, materials, quantities and the steps needed to prepare it. All this information is usually not needed when we merely refer to the dish in a conversation.
This idea is seen in the works of Barbara Liskov and Stephen Zilles regarding abstract data types and data abstraction:
What we desire from an abstraction is a mechanism which permits the expression of relevant details and the suppression of irrelevant details. In the case of programming, the use which may be made of an abstraction is relevant; the way in which the abstraction is implemented is irrelevant.
— Liskov, B.H. & Zilles, S. (1974, April). Programming with Abstract Data Types, ACM Sigplan Conference on Very High Level Languages, p. 51.
One way of thinking about abstraction is to view an object from the outside: we can see ways how we can interact with the object within our context, but we cannot directly see or affect the object’s inner structure or the way the object handles that interaction. Abelson and Sussman refer to this as the abstraction barrier in chapter 2 of Structure and Interpretation of Computer Programs (SICP): as a client of the object, we have no control past the abstraction barrier of that object. We can only interact with the protocol (or API) of an object: its collection of (public) method signatures. In most languages, this protocol can be enforced by an interface.
Liskov and Zilles explain this barrier very clearly:
When a programmer makes use of an abstract data object, he is concerned only with the behavior which that object exhibits but not with any details of how that behavior is achieved by means of an implementation. The behavior of an object is captured by the set of characterizing operations.
Implementation information (…) is only needed when defining how the characterizing operations are to be implemented. The user of the object is not required to know or supply this information.
— Liskov, B.H. & Zilles, S. (1974, April). Programming with Abstract Data Types, ACM Sigplan Conference on Very High Level Languages, p. 51.
Abstractions are Core
The most important abstractions one can find in any type of software are part of its domain. These are its core abstractions: the building blocks on which our solution is based. This is where the concepts and behaviors that are common in the business are kept, often referred to as “business logic”, unfamiliar with the underlying infrastructure. All other code exists solely to serve the use cases and the domain of the application.
It is therefore recommended to put the logic regarding a system’s purpose in the domain, using terms that best reflect the context within which the system is to be used. In Domain-Driven Design this is called the ubiquitous language:
Translation muddles model concepts, which leads to destructive refactoring of code. The indirectness of communication conceals the formation of schisms — different team members use terms differently but don’t realize it.
(…)
A project faces serious problems when its language is fractured. Domain expers use their jargon while technical team members have their own language tuned for discussing the domain in terms of design.
(…)
With a conscious effort by the team, the domain model can provide the backbone for that common language, while connecting team communication to the software implementation. That language can be ubiquitous in the team’s work.
— Evans, E. (2003). Domain-driven design, pp. 24 - 25.
Business and domain experts and developers should have a shared understanding of the system and the business processes it supports or automates. A ubiquitous language should be reflected in the domain model. This introduces a clearness of terms, reduces ambiguity and encourages collaboration between business people and developers.
On an architectural level, this enables separating the core abstractions (domain concepts, use cases) from infrastructural implementation details (request handling, storage, messaging).
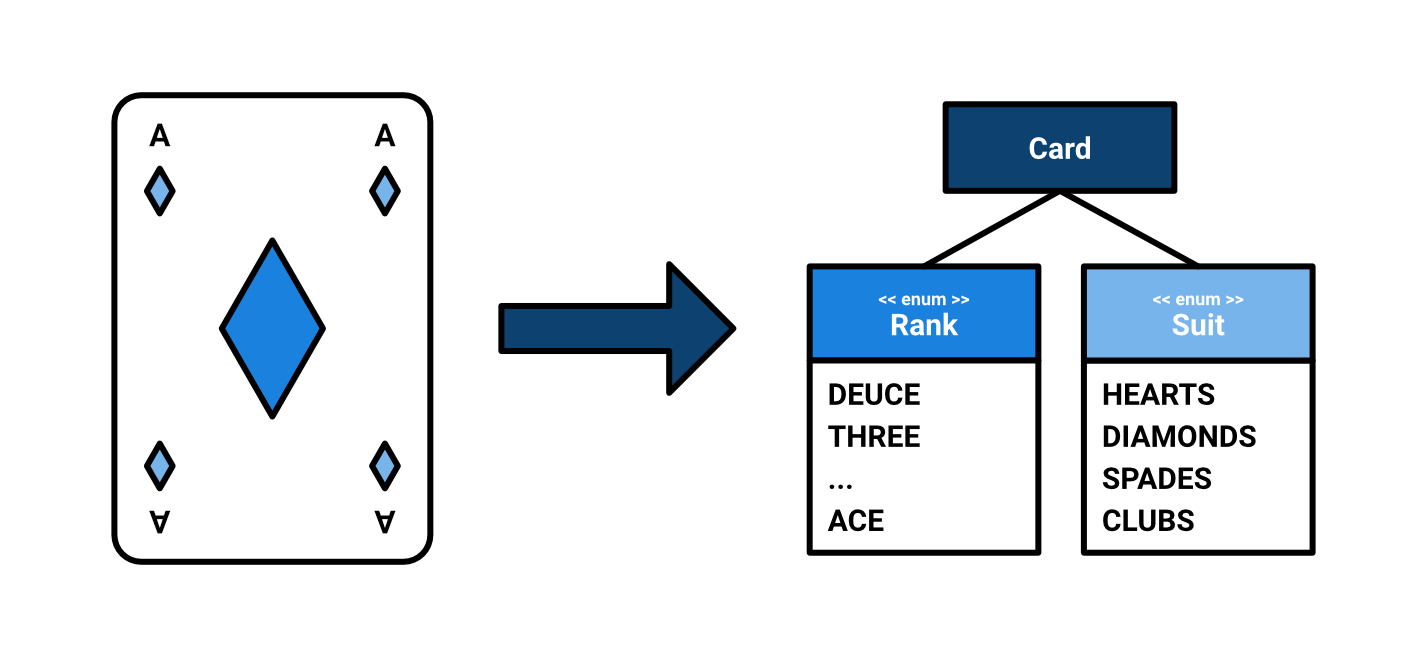
Consider a game of Texas Hold ‘em Poker. Abstractions we would find in
such a domain could be a Card with a fixed amount of possible
suits and ranks. Both are representable as enums: Suit and Rank.
We might want to be able to draw one or more cards from a Deck.
We may also want to be able to shuffle this Deck. In Poker, a Player
has a Hand of two Cards, which combined with a maximum of 3 Community cards,
is ranked against the hands of other players according to the rules of Poker.
Of course, other abstractions include chips, antes, (side)bets and the pot.
2. Encapsulation
Encapsulation and abstraction are two sides of the same coin. Abstraction is an outside view: what observable behaviors does an object have? Encapsulation is more concerned about the inside and its organization: how is the desired behavior achieved, structured, contained and published in a controlled manner?
Encapsulation is the process of compartmentalizing the elements of an abstraction that constitute its structure and behavior; encapsulation serves to separate the contractual interface of an abstraction and its implementation.
— Booch, G., e.a. (2007). Object Oriented Analysis & Design with Applications, p. 52.
A concept is represented in code as an abstraction, focussing on the things that matter for a particular domain. The outside world can interact with it through a published means of communication: its protocol, interface, API. The abstraction forms a capsule, containing the data structures and behaviors needed for doing what is requested. An object’s behaviors are found in its methods, while its state is found inside its attributes (or: fields).
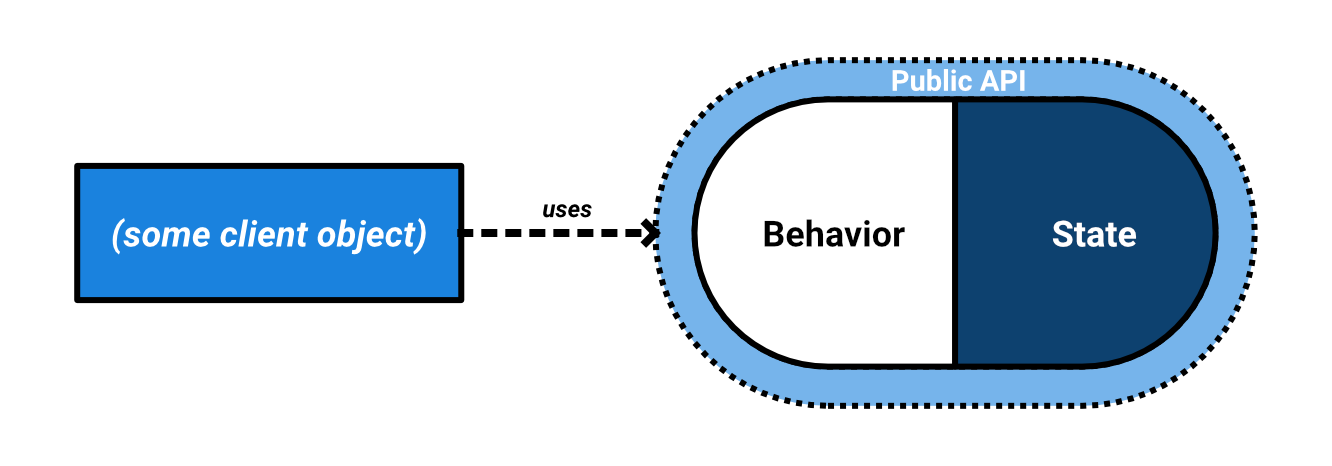
Information hiding is considered to be in line with encapsulation: we hide the internal structures and behaviors from the outside world to reduce coupling and facilitate independent design evolution over time. Parnas discussed this concept in the context of software design. He proposed not every module’s design information should be publicly accessible to (the designers of) the entire system:
We can avoid many (…) problems (…) by rejecting the notion that design information should be accessible to everyone. Instead we should allow the designers, those who specify the structure, to control the distribution of design information as it is developed.
(…)
For example, we have noted a conflict between the desire to produce a system for which the external interface is easily changed. We can avoid that conflict by designing the external interface, using it as a check on the remaining work, but hiding the details that we think likely to change from those who should not use them.
— D.L. Parnas (1971), Information distribution aspects of design, p. 342
In most OO languages, data and behaviors can be hidden
through visibility modifiers (i.e. private or protected).
Invoking a method on an object
and supplying parameters
can be seen as passing a message
to an object with some contents.
The object, upon receiving the message,
has been given the responsibility and the knowledge
to deal with that message. An object is an expert
on a certain piece of the problem or solution space.
This is what Larman (2004) refers to as the
Information Expert
(part of the GRASP patterns):
Problem
What is a general principle of assiging responsibilities to objects?
(…)
During object design, when the interactions between objects are defined, we make choices about the assignment of responsibilities to software classes. If we’ve chosen well, systems tend to be easier to understand, maintain, and extend, and our choices afford more opportunity to reuse components in future applications.
Solution
Assign a responsibility to the information expert — the class that has the information necessary to fulfill the responsibility.
— C. Larman (2004), Applying UML and Patterns, p. 248
One can compare objects’ behaviors to human interaction. This is known as anthropomorphization or the object-as-person metaphor:
The object-as-person metaphor tells us that an object needs to be an agent capable of providing a specified set of services. It has access to a body of knowledge (some of it internalized) that it uses to respond to our service requests as well as any necessary mechanisms (talents and skills) and resources (instruments, a computer or whatever else it may need). It also tells us that the (only) appropriate way to determine whether an object will suit our needs is by a careful review of its interface (résumé).
— West, D. (2004). Object Thinking, p. 102.
We regularly ask people to do things for us, to provide a service. We do not need to tell a restaurant server the details of how a certain dish is to be prepared. We do not care about how the request is fulfilled or whoever actually provides the service in the end. We tend not to favor micro-management. Often, a specialist person will relay tasks in areas outside of their interest or expertise to another person, they will use whatever tools they need to get the job done and delegate tasks to others where applicable. Servers in a restaurant collect orders, cooks make dishes. Offering a service often requires collaboration between a team of specialists. They need to communicate.
Alan Kay, who coined the term object orientation in the late 60s, often emphasizes the communication between objects when designing an object oriented system:
The key in making great and growable systems is much more to design how its modules communicate rather than what their internal properties and behaviors should be.
A typical distinction between messages can be found in Bertrand Meyer’s command/query separation (Meyer, B. (1988). Object-oriented Software Construction). One can send an object a query to request certain information or a command to make it perform some action.
Like a pure function, queries should not have any side-effects, such as changing an object’s state or performing an action. This makes queries idempotent: performing the same query twice will result in the same result given the same system state.
Commands are procedures that are allowed to have these kinds of side-effects when performing an action. Commands can return values, but there is no guarantee of idempotency. A nice guideline is that well-encapsulated code does not need a lot of queries in order to get a command done.
Applied to the game of Poker, we have a Game object as the
primary entry point for our domain. This Game can be persisted over time.
In Domain-Driven Design terms, it can be
considered the Aggregate Root.
It presents the primary actions to
perform the use cases of our system on.
For instance, we can start a new round and, depending on the phase,
a player could choose to bet, call, raise or fold.
To apply these actions to specific operations, the Game
refers to the Deck, the CommunityCards and each Player.
A Player knows how to increase his or her bet and
add a Card to its Hand after it has been drawn from the Deck.
A HandRanking implementation knows how each hand stacks up,
leaving it to the Game to pay-out the bet to the winner(s).
Do not Break Encapsulation
In “modern projects”, developers tend to default to adding accessors and mutators (getters and setters), to each and every class (sometimes even through specific annotations). This is a shame. Do we really need access to an object’s internal state, it’s attributes? Or can we offer the desired behaviors without callers needing to reach inside? Unless its a Data Transfer Object (DTO), getters and setters weaken encapsulation and endanger the clarity of our design.
If we choose to add mutators, it would also be a better
idea to consider whether we can express such need in a method
name that reflects the operation more in terms of the business domain.
Doesn’t player.rename(name) better reflect an object’s intent
and a solution’s domain than player.setName(name)?
It surely sounds less robotic!
The encapsulation break caused by getters-and-setters-based code is worsened when developers don’t let objects do the work. This occurs when we operate primarily outside of the objects, acquiring our operands through the object’s getters and putting the result back into the object via its setters. Such code does not respect the principle of Tell, don’t Ask.
For instance, code like this is, sadly, fairly common:
List<Card> cards = deck.getCards();
Random random = new Random();
Card randomCard = cards.get(random.nextInt(cards.size()));
player.getHand().getList().add(randomCard);
What does this code do? Well, obviously, it selects a random card! But isn’t there a more clear and thoughtful way of representing this? Something that not only respects encapsulation, but also aligns with the language of card games?
// Generate a full deck of 52 cards (static factory method)
// and inject the pseudo-random number generator
// (this allows for determinism when testing using a test double)
Deck deck = Deck.full(new Random());
Card card = deck.drawRandomCard();
Of course, we could also pass the randomness to the drawRandomCard
method. There is no need to inject it as a dependency in the
static factory method (named constructor).
Another command we would like the deck to perform, could be to shuffle it and then just take the first card on top.
Deck deck = Deck.full(new Random());
// Shuffle the entire deck, then draw a card
deck.shuffle();
Card card = deck.draw();
// Add the card to the player's hand
player.take(card);
Encapsulation breaks when the outside world not only knows about the insides of an object, but also of the insides of the insides of an object — or worse. This violates the Law of Demeter.
Let’s have a look at the following code. It determines whether a player has two cards of the same Suit (hearts, diamonds, spades or clubs).
public boolean hasSuitedHand(Player player) {
return player.getHand().getList().get(0).getSuit().equals(player.getHand().getList().get(1).getSuit());
}
Sometimes referred to as train wrecks, this code consists of
a lot of data being shifted around in order
to perform a command or query.
Strictly speaking, we need to know the
internal structure of Player, Hand, List and Card from wherever
this code is called. This couples calling code to the internal structure
of our abstractions.
Our outside code is guaranteed to break if the internal
structure changes – which it will; such is the nature of software.
Using temporary variables is more readable (our variable names make its intention clear), but is still a train wreck encapsulation-wise:
public boolean hasSuitedHand(Player player) {
var firstCardSuit = player.getHand().getList().get(0).getSuit();
var secondCardSuit = player.getHand().getList().get(1).getSuit();
return firstCardSuit.equals(secondCardSuit);
}
We should not need to know about the internal structure of a player and their hand! Depend on the boundaries of the abstraction, instead of looking through it! We can respect encapsulation a bit more by letting objects do the work. Let’s just ask the player if they have a suited starting hand and make it an Information Expert!
Inside the Player class, we would have:
public boolean hasSuitedHand() {
return this.hand.getList().get(0).getSuit().equals(this.hand.getList().get(1).getSuit());
}
This is slightly better as it encapsulates at the boundary of a player. Let’s go all the way, by leveraging our other, now internalized, abstractions and making them Information Experts of their assigned responsibility! We would like to have something like this:
public boolean hasSuitedHand() {
return this.hand.isSuited();
}
This means we need to put the knowledge in the classes that know most about the necessary concepts needed to perform the operation. An (anthropomorphized) hand, within the context of a card game, knows what cards it holds and what it can do with those cards. We can also make the cards a bit smarter and allow a comparison by suit:
public boolean isSuited() {
return this.cards.get(0).hasSameSuit(this.cards.get(1));
}
Or, more generally, if we were to support more cards:
public boolean isSuited() {
Card card = this.card.get(0);
for (Card other : this.cards) {
if (!card.hasSameSuit(other)) {
return false;
}
}
return true;
}
Whichever implementation we choose,
the abstraction remains the same! Callers are coupled to
the API, the method signatures, of our Hand class and
not to its internal structure or algorithm.
These kinds of dedicated, behavior-focused methods
are also easy to test independently. Automated tests allow
for easy detection of regressions,
for instance when we restructure or optimize the implementation.
3. Modularity
We can divide our system into groups of related behaviors and data structures. In object-oriented languages, the primary units of (de)composition are objects and, in most languages, the classes they instantiate. Their abstract representation is separated from their implementation details by hiding their inner behaviors and data structures through encapsulation behind a public API.
Booch, e.a. define modularity as follows:
Modularity is the property of a system that has been decomposed into a set of cohesive and loosely coupled modules.
— Booch, G., e.a. (2007). Object Oriented Analysis & Design with Applications, p. 56.
Booch, e.a. remark that abstraction, encapsulation and modularity work nicely together: “An object provides a crisp boundary around a single abstraction, and both encapsulation and modularity provide barriers around this abstraction.” We strive for modules such as classes to be highly cohesive (its constituents work together for comparable outcomes), while being loosely coupled from other modules.
Modularity beyond Classes
Languages usually also offer a way of grouping related units in the way of packages, assemblies, namespaces or modules. Units can be grouped and named based on their role or abstraction level within the system. This separation of concerns is very useful when designing maintainable systems as it makes its purposes explicit.
Grouping structures can usually be mapped to higher-level, meaningful architectural concepts. For instance, components (or: (micro)services) are often used to group similar aspects of functionality (i.e. related use cases). A component can be subdivided in layers in order to offer a logical separation by concern and level of abstraction. Subsystems can then be used to group related concepts within a certain layer.
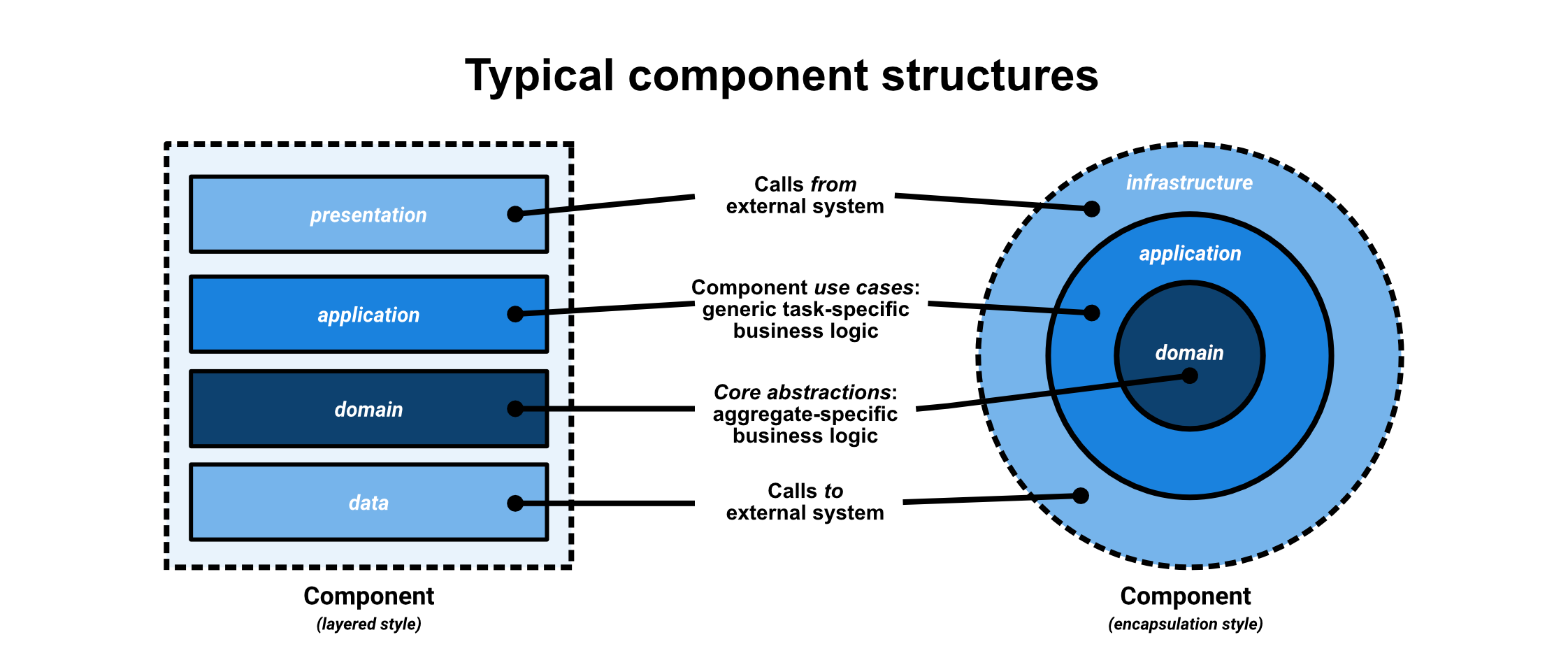
A class that deals with storing the current state of a poker game in a database is part of a very concrete layer that deals with external infrastructure, while a class that defines the ranking of poker hands with regards to our domain is more abstract. These two classes are in separate levels of abstraction. We can reflect this in layers. For instance, anything that deals with the outside world can be put in an infrastructure or data layer, while our core domain can be part of our domain layer.
It is a good idea to let your package or namespace structure reflect your high-level architecture, rather than mere technical concerns. This is similar to what some call screaming architecture, although I focus on a semantically rich modular architecture in which each package has meaningful architectural role. This can help when exploring, enforcing and checking architectural rules. See: L. Pruijt, C. Köppe & S. Brinkkemper (2013), “Architecture Compliance Checking of Semantically Rich Modular Architectures: A Comparative Study of Tool Support”.
I recommend starting out by identifying the core functionalities (or subdomains) of your system. These can be its components. Each component can then have its own layers and each layer its own subsystems. This intentful organization of abstractions can lead to a more understandable project structure.
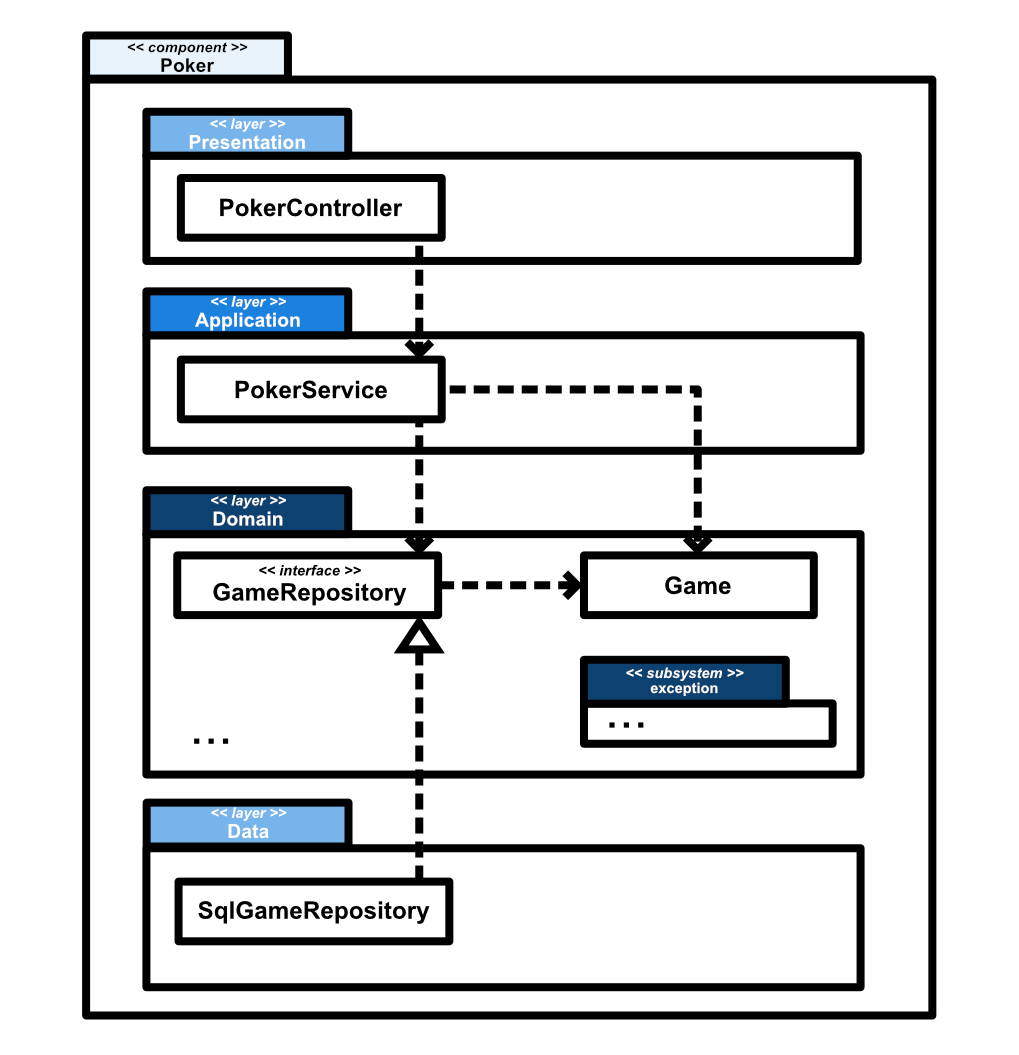
Thinking about the responsibilities rather than the concrete steps in order to design collaborating yet loosely coupled and cohesive modules is nothing new. As Parnas concludes his influential 1972 paper which birthed the idea of “Parnas modules”:
(…) [I]t is almost always incorrect to begin the decomposition of a system into modules on the basis of a flowchart.
We propose instead that one begins with a list of difficult design decisions or design decisions which are likely to change. Each module is then designed to hide such a decision from the others. Since, in most cases, design decisions transcend time of execution, modules will not correspond to steps in the processing. To achieve an efficient implementation we must abandon the assumption that a module is one or more subroutines, and instead allow subroutines and programs to be assembled collections of code from various modules.
— D.L. Parnas (December, 1972). On the Criteria To Be Used in Decomposing Systems into Modules, Communications of the ACM, p. 1058
4. Hierarchy
This brings us in the area of hierarchy, the last major element of Booch' object model: organizing abstractions by combining them in some way.
Hierarchy is a ranking or ordering of abstractions.
— Booch, G., e.a. (2007). Object Oriented Analysis & Design with Applications, p. 58.
We have already seen a way of creating hierarchy by organizing our packages or namespaces meaningfully, by discerning components, layers and subsystems.
On a more detailed level, languages offer tools that allow certain relationships to exist between classes. These relationships are important to think about as they are sources of coupling. Parnas, when discussing organizational information hiding when designing modules, spoke of connections:
The connections between modules are the assumptions which the modules make about each other.
(…)
The meaning of the above remark can be exhibited by considering two situations in which the structure of a system is terribly important: (1) making of changes in a system and (2) proving programs correct.
— D.L. Parnas (1971), Information distribution aspects of design, p. 339-340.
We can describe these relationships in our model to give meaning to how the objects of certain classes will interact. The most common relationships we can design with are dependency, association, composition, aggregation, generalization and realization.
Dependency (uses)
A dependency is a very general relationship. It means that the functionality of an object of some class is used by an object of another class. It is a unidirectional relationship: the user (client) depends on the used (provider), not the other way around.
A dependency is a using relationship that states that a change in specification of one thing (…) may affect another thing that uses it, but not necessarily the reverse.
— Booch, G., e.a. (1999). The unified modeling language user guide: UML, p. 63.
This is creates a common type of coupling: changes in the code for the class that is depended upon can result in changes in the code of the dependent class.
Association (is-connected-to)
If two or more classes are structurally connected, this is called an association. For example, when an object stores another object in one of its attributes, it is typically an association.
An association is a structural relationship that specifies that objects of one thing are connected to objects of another. Given an association connecting two classes, you can navigate from an object of one class to an object of the other class and vice versa.
— Booch, G., e.a. (1999). The unified modeling language user guide: UML, p. 66.
An association can be unidirectional, meaning that an object contains another object in one or more of its attributes, but not the other way around. In a bidirectional association, the containment goes both ways: objects of the one class can contain objects of the other class and objects of the other class can contain objects of the one class.
We can model associations more extensively by writing down the role it fulfills in the structure or by noting the multiplicity of the association. An association’s role is commonly depicted by writing down the name of the field or attribute to be found in the owning class.
The multiplicity indicates how many objects
can be expected in the association, using a
minimum bound and a maximum bound. These can be
filled in by an actual number (0, 1, 6) or
can be unbound (*).
In UML, aggregation and composition are specific forms of assocation: ways of more strictly modelling a certain relationship between the objects of two classes.
Aggregation (has-a)
Aggregation is a specific kind of association, qualifying one class as the whole and other classes as its parts.
Sometimes, you will want to model a “whole/part” relationship, in which one class represents a larger thing (the “whole”), which consists of smaller things (the “parts”). This kind of relationship is called aggregation, which represents a “has-a” relationship, meaning that an object of the whole has objects of the part.
— Booch, G., e.a. (1999). The unified modeling language user guide: UML, p. 67.
Aggregation does not necessarily tie the lifetime of the container to the lifetime of its contained parts and a part of one aggregation can still be part of another aggregation.
Composition (is-only-part-of)
Another kind of association is composition. In terms of the UML, composition is a stricter form of aggregation.
Composition is a form of aggregation, with strong ownership and coincident lifetime as part of the whole. Parts with non-fixed multiplicity may be created after the composite itself, but once created they live and die with it. Such parts can also be explicitly removed before the death of a composite.
This means that, in a composite aggregation, an object may be part of only one composite at a time. (…) This is in contrast to simple aggregation, in which a part may be shared by several wholes. (…) In addition, in composite aggregation (…) the composite must manage the creation and destruction of its parts.
— Booch, G., e.a. (1999). The unified modeling language user guide: UML, p. 147.
Within the context of UML, composition gives the container exclusive ownership over the contained parts. This means a part can only belong to one whole at a time. Composition also ties the lifetime of the parts to the lifetime of the container. If the container is destroyed, its contained parts are also destroyed. The contained parts are typically only accessed through the container and not independently.
In practice, composition is often used as a more general term for the has-a relationship — comparable to UML’s concept of aggregation. This can be very confusing at times, which is why I like to talk about UML-composition or strict composition when talking about this relationship.
For instance, “favor composition over inheritance”, the adage from the Design Pattern book by the Gamma e.a. (1994), is not to be interpreted as to use composite aggregation over inheritance. Rather, one should favor the has-a relationship over the is-a relationship for achieving re-use rather than sharing a general, concrete superclass. Implementation inheritance often introduces more coupling than desired (i.e. between siblings and between predecessors and successors). This is something to be mindful of as it can make future changes difficult as opposed to has-a relationships which enable flexible re-use by depending on abstract/virtual classes or interfaces. As we will discuss, through realization and polymorphism the “parts” in a has-a relationship can be flexibly filled in as required. The same holds for the general concept of function composition.
Generalization (is-a-kind-of)
Generalization typically means the existance of a parent/child relationship: there is some kind of superclass (the parent), the general case, and one or more subclasses (the children), its specializations.
A generalization is a relationship between a general thing (…) and a more specific kind of that thing.
(…)
Generalization means that objects of the child may be used anywhere the parent may appear, but not the reverse.
— Booch, G., e.a. (1999). The unified modeling language user guide: UML, p. 65.
Generalization is typically used to show implementation inheritance: a subclass can inherit general attributes and methods from their superclass.
Realization (implements)
When we implement a certain interface or abstract/virtual class or method in a class, that class has a realization relationship with its superclass or interface.
A realization is a semantic relationship between classifiers in which one classifier specifies a contract that another classifier guarantees to carry out.
— Booch, G., e.a. (1999). The unified modeling language user guide: UML, p. 149.
Realization is typically used to show interface inheritance: a class implements a certain interface or fills in (parts of) an abstract/virtual class.
Polymorphism
Realization and generalization are ways of expressing polymorphism. This word stems from the Greek words “πολῠ́ς” (“many” or “a lot”) and “μορφή” (“shape” or “form”). In the context of software it means: one abstraction can appear in many forms. A superclass can have many subclasses. An interface can have many implementations.
Strongly typed languages offer ways of enforcing the behaviors that are required of an abstraction through protocols, such as interfaces, type classes and type constraints.
The idea of depending on abstractions instead of implementation details can be extended to these higher abstractions. Polymorphism is highly beneficial to the flexibility of a system. When an object depends on an abstraction, the details can be filled in by its implementing subtype. This is why Gamma, e.a. (1996) advise to “program to an interface, not an implementation” in the Design pattern book. In addition, favoring composition over inheritance, we end up with flexible software by making the “whole” rely on interfaces or abstract/virtual classes for its “parts”.
Programming to an interface or, more generically, a supertype, follows the principle of least commitment, as noted by Abelson and Sussman (SICP 2.4). The barrier formed by a certain abstract representation of a concept in code permits a developer to defer the choice of a concrete representation to the last possible moment. This allows flexibility when designing a system. For instance, one can start off with a basic storage solution and switch out this solution later on by simply reimplementing and filling in the abstractions — when requirements and perspectives change and the team learns. Both implementations are realizations of the same protocol.
Conclusion
In this post, we looked at object-oriented design through the lens of the Object Model.
Object orientation entails finding the right abstractions that work together to solve problems. Every abstraction has a certain responsibility for which it is an information expert.
An abstraction should only contain the state and behaviour necessary to fulfill its assigned role (encapsulation). It hides its inner workings to reduce coupling. Instead of pulling data out of an abstraction, we let that abstraction do the work (Tell, don’t Ask). This way we do not create train wrecks, but respect the Law of Demeter.
Through modularization, we end up with a set of cohesive and decoupled modules, such as methods, classes, packages and entire applications. We can organize them in a clear manner by separating and grouping them by their concerns such as their level of abstraction and responsibility.
To clearly define the levels of abstractions and the responsibilities in our system’s structure, we can discern components, layers and subsystems. This introduces a meaningful hierarchy on a package or namespace level. We can intentfully design a hierarchy of modules by qualifying the relationships between them, such as dependency, association, aggregation, composition, generalization and realization.
We build flexible software by programming to an interface and favoring composition over inheritance, allowing the whole of our software to be constituted of replacable parts through the power of polymorphism. This also allows us to defer certain design decisions to later, in line with the principle of least commitment.
Thoughts?
Leave a comment below!